![[이코테] 5. DFS & BFS](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2Fnk2cP%2FbtrXOtqP2W3%2FKTRjuKZrCDJ4lGvx59ILN1%2Fimg.png)
DFS/BFS
- DFS/BFS = 대표적인 그래프 탐색 알고리즘.
- 코딩테스트에 꼭 나오는 유형.
- 탐색 = 많은 양의 데이터 속에서 원하는 데이터를 찾는 과정
- DFS/BFS를 알기위한 사전 개념으로 스택과 큐에 대해서 알아야함.
스택과 큐 자료구조
스택과 큐를 설명하라고 한다면, 이것 부터 떠올려라!
- 스택 : 막힌 통(프링글스 통) / 선입후출
- 큐 : 뚫린 통(터널) / 선입선출
Python에서 스택 자료구조를 이용하려면, list 를 사용하면 된다.
stack = []
# 삽입(5) - 삽입(2) - 삽입(3) - 삽입(7) - 삭제() - 삽입(1) - 삽입(4) - 삭제()
stack.append(5)
stack.append(2)
stack.append(3)
stack.append(7)
stack.pop()
stack.append(1)
stack.append(4)
stack.pop()
print(stack[::-1]) # 최상단 원소부터 출력 [start:end:step]
print(stack) # 최 하단 원소부터 출력
Python에서 큐 자료구조를 이용하려면 deque을 사용하면 된다. (뎈?!)
from collections import deque
# 큐(Queue) 구현을 위해 deque 라이브러리 사용
queue = deque()
# 삽입(5) - 삽입(2) - 삽입(3) - 삽입(7) - 삭제() - 삽입(1) - 삽입(4) - 삭제()
queue.append(5)
queue.append(2)
queue.append(3)
queue.append(7)
queue.popleft()
queue.append(1)
queue.append(4)
queue.popleft()
print(queue) # 먼저 들어온 순서대로 출력
queue.reverse() # 역순으로 바꾸기
print(queue) # 나중에 들어온 원소 부터 출력list를 활용해서 큐를 구현할 수 있지만, 시간복잡도 측면에서 더 비효율적인 동작할 수 있기 때문에 deque사용.
append는 오른쪽에 데이터 쌓는 역할
popleft는 가장 왼쪽에 있는 데이터 뽑아내고자 할 때 사용.
재귀함수(Recursive Function)
재귀 함수란?
- 자기 자신을 다시 호출하는 함수.
- 'Recursive하게 동작하도록 프로그램을 작성하라!!' -> 재귀 함수를 사용해서 해결하라는 뜻
- while, for문 사용하지 않고도 재귀적 방법을 통해 해결 가능. (단, 종료조건 必)
- 구동 원리가 프링글스 통(스택)이랑 유사.
- 그래서 스택을 사용해야 할 때, 구현 상 스택 라이브러리 대신 재귀 함수를 이용하는 경우 다수.
- 함수를 연속적으로 호출한다면, 컴퓨터 메모리 내부의 스택 프레임에 데이터가 쌓임.
- 해당 메모리 소모를 줄이고자 Max값 설정 되어 있음.
단순한 형태의 재귀 함수 예제
def recursive_function():
print('재귀 함수를 호출합니다.')
recursive_function()
recursive_function()
''' output
재귀 함수를 호출합니다.
재귀 함수를 호출합니다.
..
재귀 함수를 호출합니다.
Traceback (most recent call last):
File "/usr/local/lib/python3.6/dist-packages/IPython/core/interactiveshell.py", line 3343, in run_code
exec(code_obj, self.user_global_ns, self.user_ns)
File "<ipython-input-3-c6c8c5bc4a47>", line 1, in <module>
recursive_function()
File "<ipython-input-2-daf81928025a>", line 3, in recursive_function
recursive_function()
File "<ipython-input-2-daf81928025a>", line 3, in recursive_function
recursive_function()
File "<ipython-input-2-daf81928025a>", line 3, in recursive_function
recursive_function()
[Previous line repeated 2982 more times]
File "<ipython-input-2-daf81928025a>", line 2, in recursive_function
print('재귀 함수를 호출합니다.')
RecursionError: maximum recursion depth exceeded while calling a Python object
''''재귀 함수를 호출합니다.' 라는 문자열 무한 출력 하는 예제임.
but, 최대 재귀 깊이 초과 Error 발생.
재귀 함수는, 스택 자료구조 안에 함수에 대한 정보를 담아서 컴퓨터 메모리에 올라간다.
재귀 함수는, for/while문과 마찬가지로 빠르게 메모리가 가득 찬다.
그래서 재귀 깊이 제한을 걸어 둔 것이다.
우리는 이를 해결하려면 종료 조건을 만들거나, 제한의 폭을 늘리는 방법을 사용해야한다.
코딩테스트에서는 무한 루프가 이루어질 정도로 주어지지 않으며, 종료 조건을 반드시 명시해야한다.
재귀 함수의 종료 조건
def recursive_function(i):
# 100번째 호출을 했을 때 종료되도록 종료 조건 명시
if i == 100:
return
print(i, '번째 재귀함수에서', i + 1, '번째 재귀함수를 호출합니다.')
recursive_function(i+1)
print(i, '번째 재귀함수를 종료합니다.')
recursive_function(1)
''' output
1 번째 재귀함수에서 2 번째 재귀함수를 호출합니다.
2 번째 재귀함수에서 3 번째 재귀함수를 호출합니다.
3 번째 재귀함수에서 4 번째 재귀함수를 호출합니다.
..
98 번째 재귀함수에서 99 번째 재귀함수를 호출합니다.
99 번째 재귀함수에서 100 번째 재귀함수를 호출합니다.
99 번째 재귀함수를 종료합니다.
98 번째 재귀함수를 종료합니다.
..
1 번째 재귀함수를 종료합니다.
'''재귀 함수를 이용하게 되면,
마치 프링글스 통에 데이터를 넣었다가 꺼내는 것과 같이 느껴짐.
실제로, 재귀함수는 스택에 함수에 대한 정보를 담음.
재귀 함수 예제
팩토리얼 구현, 최대공약수 계산을 재귀 함수로 구현한 예제를 살펴 보겠다.
팩토리얼 구현 예제
####################
# 반복적으로 구현한 n! #
####################
def factorial_iterative(n):
result = 1
# 1부터 n까지의 수를 차례대로 곱하기
for i in range(1, n + 1):
result *= i
return result
####################
# 재귀적으로 구현한 n! #
####################
def factorial_recursive(n):
if n<= 1: # n이 1이하인 경우 1 반환, => 왜?. 1! = 0! = 1,,
return 1
# n! = n * (n-1)!를 그대로 코드로 작성하기
return n * factorial_recursive(n-1)
# 각각의 방식으로 구현한 n! 출력(n=5)
print('반복적으로 구현:', factorial_iterative(5))
print('재귀적으로 구현:', factorial_recursive(5))
'''output
반복적으로 구현: 120
재귀적으로 구현: 120
'''
최대공약수 계산 (유클리드 호제법) 예제
유클리드 호제법이란?
두 개의 자연수에 대한 최대 공약수를 구하는 대표적인 알고리즘.
두 자연수 A, B에 대하여 (A > B일 경우) A를 B로 나눈 나머지를 R이라 한다.
이때, A와 B의 최대 공약수는 B와 R의 최대 공약수와 같다.
유클리드 호제법의 아이디어를 그대로 재귀 함수로 작성할 수 있다.
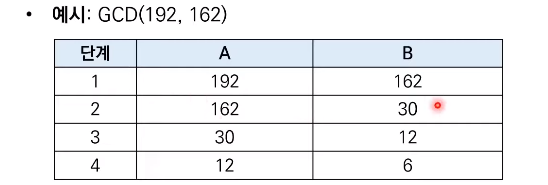
def gcd(a, b):
if a % b == 0:
return b
else:
return gcd(b, a % b)
print(gcd(192, 162))
'''output
6
'''
재귀 함수 사용의 유의사항
- 재귀 함수를 잘 활용하면 복잡한 알고리즘을 간결하게 작성할 수 있음.
- 단, 오히려 다른사람이 이해하기 어려운 형태의 코드가 될 수 있으므로 신중히 사용할 것
- 모든 재귀 함수는 반복문을 이용하여 동일한 기능 구현 가능.
- 재귀 함수가 반복문 보다 유리한 경우도 있고, 불리한 경우도 있음.
- 컴퓨터가 함수를 연속적으로 호출하면 컴퓨터 메모리 내부의 스택 프레임에 쌓인다.
- 그래서 스택을 사용해야 할 때 구현상 스택 라이브러리 대신에 재귀 함수를 이용하는 경우가 많다.
DFS(Depth-First Search)
DFS란?
- '깊이 우선 탐색'이라고 부름
- 그래프 에서 깊은 부분을 우선적으로 탐색하는 알고리즘
- 스택 자료구조(혹은 재귀 함수)를 이용하며, 구체적인 동작 과정은 아래와 같음
- 탐색 시작 노드를 스택에 삽입하고 방문 처리한다.
- 스택의 최상단 노드에 방문하지 않은 인접한 노드가 하나라도 있으면 그 노드를 스택에 넣고 방문 처리한다. 방문하지 않은 인접 노드가 없으면 스택에서 최 상단 노드를 꺼낸다.
- 더 이상 2번의 과정을 수행할 수 없을 때 까지 반복.
동작 과정 시각화 예시







DFS 기본 예제
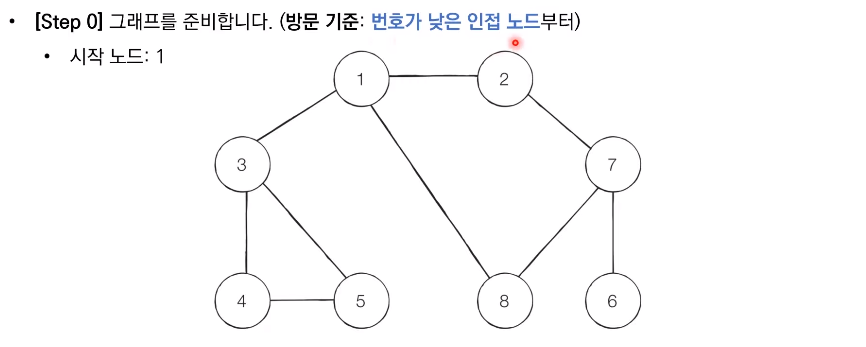
실행 결과 : 1 2 7 6 8 3 4 5
소스코드
# DFS 메서드 정의
def dfs(graph, v, visited):
# 현재 노드 방문 처리
visited[v] = True
print(v, end=' ')
# 현재 노드와 연결된 다른 노드를 재귀적으로 방문
for i in graph[v]:
if not visited[i]:
dfs(graph, i, visited)
# 각 노드가 연결된 정보를 표현 (2차원 리스트)
graph = [
[], # 0번은 비워둠
[2, 3, 8], # 1번 노드와 인접한 노드 번호를 리스트로 만들어 초기화 함.
[1, 7], # 2번 노드는 1번, 7번 노드와 인접
[1, 4, 5],
[3, 5],
[3, 4],
[7],
[2, 6, 8],
[1, 7]
]
# 각 노드의 방문 처리 표현 (1차원 리스트)
visited = [False] * 9
# 정의된 DFS 함수 호출
dfs(graph, 1, visited)
'''output
1 2 7 6 8 3 4 5
'''
파이썬에서는 그래프를 표현하기 위해 2차원 리스트를 활용하여 표현할 수 있음.
일반적으로 그래프문제가 출제되면
노드의 번호가 1번부터 시작되는 경우가 많기 때문에
index 0에 해당하는 부분은 비워두도록 하고,
1번 인덱스부터 해당 노드와 인접한 노드가 무엇인지 리스트로 나타냄. (graph 선언부분)
방문처리를 위해서 하나의 1차원 리스트를 만듦.
단, 여기에서 기본적으로 모든 값들은 False값으로 초기화해서
처음에는 모든 노드를 하나도 방문하지 않은 것처럼 표현.
다만, 1번 노드부터 8번까지 가지고있는데
index 0은 사용하지 않도록 하기 위해서 일부러 하나더 큰 크기로 1차원 리스트 초기화함
(각각의 노드에서 1을 뺀 값으로 처리하는 경우도 있긴 있지만, index0은 사용하지 않는 방식을 쓰는게 문제에 나와있는 노드 번호를 그대로 index형태로 매핑할 수 있기 때문에 더 헷갈리지 않고 직관적일 수 있다.) (visited = [False] * 9 부분)
DFS 응용 예제, 음료수 얼려 먹기
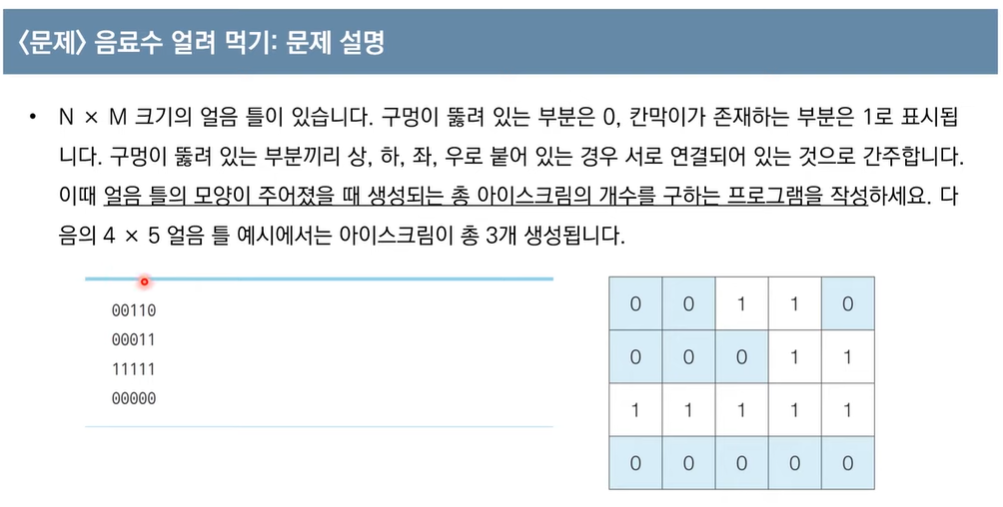

소스코드
def dfs(x, y):
if x <= -1 or x >= n or y <= -1 or y >= m:
return False
if graph[x][y] == 0:
graph[x][y] = 1
dfs(x - 1, y)
dfs(x, y - 1)
dfs(x + 1, y)
dfs(x, y + 1)
return True
return False
n, m = map(int, input().split())
graph = []
for i in range(n):
graph.append(list(map(int, input())))
result = 0
for i in range(n):
for j in range(m):
if dfs(i, j) == True:
result += 1
print(result)
'''output
3
'''
BFS(Breadth-First Search)
BFS란?
- '너비 우선 탐색'이라고 부름
- 그래프에서 가까운 노드부터 우선적으로 탐색하는 알고리즘
- 큐 자료구조를 이용하며, 구체적인 동작 과정은 아래와 같음
- 탐색 시작 노드를 큐에 삽입하고 방문 처리한다.
- 큐에서 노드를 꺼낸 뒤에 해당 노드의 인접 노드 중에서 방문하지 않은 노드를 모두 큐에 삽입하고 방문 처리.
- 더 이상 2번의 과정을 수행할 수 없을 때 까지 반복.
- 특정 조건에서의 최단 경로 문제를 해결하기 위한 목적으로도 효과적으로 사용 가능. (코테에서 자주 나옴)
BFS 기본 예제
실행 결과 : 1 2 3 8 7 4 5 6
소스코드
from collections import deque
# BFS 메서드 정의
def bfs(graph, start, visited):
# 큐(Queue) 구현을 위해 deque 라이브러리 사용
queue = deque([start])
# 현재 노드를 방문 처리
visited[start] = True
# 큐가 빌 때까지 반복
while queue:
# 큐에서 하나의 원소를 뽑아 출력하기
v = queue.popleft()
print(v, end=' ')
# 아직 방문하지 않은 인접한 원소들을 큐에 삽입
for i in graph[v]:
if not visited[i]:
queue.append(i)
visited[i] = True
# 각 노드가 연결된 정보를 표현 (2차원 리스트)
graph = [
[],
[2, 3, 8],
[1, 7],
[1, 4, 5],
[3, 5],
[3, 4],
[7],
[2, 6, 8],
[1, 7]
]
# 각 노드가 방문된 정보를 표현 (1차원 리스트)
visited = [False] * 9
# 정의된 BFS 함수 호출
bfs(graph, 1, visited)
'''output
1 2 3 8 7 4 5 6
'''
BFS 응용 예제, 미로 탈출

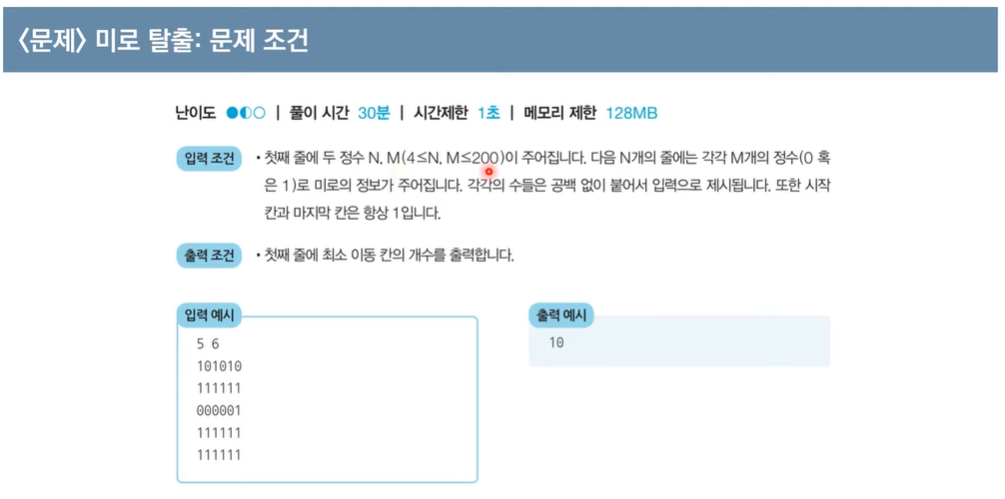
소스코드
from collections import deque
# BFS 소스코드 구현
def bfs(x, y):
# 큐 구현을 위해 deque 라이브러리 사용
queue = deque()
queue.append((x, y))
# 큐가 빌 때까지 반복하기
while queue:
x, y = queue.popleft()
# 현재 위치에서 4가지 방향으로의 위치 확인
for i in range(4):
nx = x + dx[i]
ny = y + dy[i]
# 미로 찾기 공간을 벗어난 경우 무시
if nx < 0 or nx >= n or ny < 0 or ny >= m:
continue
# 벽인 경우 무시
if graph[nx][ny] == 0:
continue
# 해당 노드를 처음 방문하는 경우에만 최 단거리 기록
if graph[nx][ny] == 1:
graph[nx][ny] = graph[x][y] + 1
queue.append((nx, ny))
# 가장 오른쪽 아래 까지의 최단 거리 반환
return graph[n - 1][m - 1]
# N, M을 공백을 기준으로 구분하여 입력받기
n, m = map(int, input().split())
# 2차원 리스트의 맵 정보 입력 받기
graph = []
for i in range(n):
graph.append(list(map(int, input())))
# 이동할 네 가지 방향 정의 (상, 하, 좌, 우)
dx = [-1, 1, 0, 0]
dy = [0, 0, -1, 1]
print(bfs(0, 0))
'''output
10
'''

이코테 2021 시리즈 씹어먹기 by 조랭이떡
시리즈 목차
- 코딩테스트 출제 경향 및 알고리즘 성능 평가
- 파이썬 문법 부수기
- 그리디
- 구현
- DFS & BFS (추후링크)
- 정렬 알고리즘 (추후링크)
- 이진 탐색 (추후링크)
- 다이나믹 프로그래밍 (추후링크)
- 최단 경로 알고리즘 (추후링크)
- 기타 그래프 이론 (추후링크)
- 코딩 테스트에서 자주 출제되는 기타 알고리즘 (추후링크)
- 개발형 코딩 테스트 (추후링크)