

2장 에서는 몇가지 기본적인 OpenCV 기능을 살펴본다.
목차.
앞서 머신러닝은 인공지능의 하위 분야로 설명했음.
이러한 명제는 사실이지만, 대부분의 경우 머신러닝은 단순히 데이터를 이해하는 과정에 불과함.
그러므로 머신러닝을 데이터 과학의 하위 분야로 생각하는 것이 더 적합.
여기서는 데이터를 이해하는데 도움이 되는 수학적 모델을 구축해봄.
2장에서 다루는 내용은 아래와 같음.
- 일반적인 머신러닝 워크플로 이해
- 훈련 데이터와 테스트 데이터 이해
- OpenCV와 파이썬으로 데이터를 적재, 저장, 편집, 시각화하는 방법 학습
머신러닝 워크플로의 이해
앞서 언급했듯이, 머신러닝에서는 데이터를 이해하기 위한 수학 모델을 구축해야 함.
학습이라는 측면은 머신러닝 모델에서 내부 매개변수를 조정하는 과정임.
모델이 데이터를 더 잘 이해할 수 있도록 매개변수를 조정하는 것임.
이제 단계별로 생각해보자.
우선, 주의해야 할 점은 머신러닝 문제는 항상 (적어도) 두 개의 개별 단계로 분리된다는 것이다.
- 훈련 단계
- 머신러닝 모델을 훈련시키고자 훈련 데이터 세트라고 불리는 일련의 데이터를 사용하는 훈련 단계가 첫번째 단계.
- 테스트 단계
- 테스트 데이터 세트라고 부르는 이전에 본 적 없는 새로운 데이터 세트를 사용해 학습된 (또는 최종) 머신러닝 모델을 평가하는 테스트 단계가 그 다음이다.
여기서 다음으로 주목해야 할 점은, 머신러닝은 데이터에 대한 모든 것을 다룬다는 것임.
데이터는 원시 형식으로 입력되고, 훈련 및 테스트 단계에서 사용됨.
원시 형식의 데이터는 픽셀, 문자, 단어 또는 비트 등등을 의미.
이러한 원시 형식의 데이터는 작업하기에 편리하지 않음,
따라서, 대신 데이터를 미리 구문 분석해서 데이터를 파싱하거나 사용하기 쉬운 형식으로 가져와야 하고, 이를 데이터 전처리라고 한다.
데이터 전처리는 아래와 같은 두 단계로 진행됨.
- 특징 선택 (feature selection)데이터에서 중요한 속성(또는 기능)을 식별하는 프로세스SURF(Speeded Up Robust Feature) 또는 HOG(Histogram of Oriented Gradient)의 히스토그램처럼 OpenCV가 제공하는 고급 특징 기술자(advanced feature descriptor)에 익숙해져야함.
ex) 깨끗한 물과 더러운 물을 구별하는 것에서 가장 중요한 특징은 '물의 색'이라 SURF or HOG기능은 별로 도움이 안되지.
- 이러한 기능은 모든 이미지에 적용할 수 있지만, 특정 작업에는 중요하지 않을 수도 있음.
- 이미지에서의 주요 특징(feature)은 가장자리, 모서리, 또는 융기(ridge) 등등을 의미.
- 특징 추출 (feature extraction)실제 데이터를 원하는 특징 공간으로 변환하는 프로세스
- 이미지의 모서리(즉, 선택된 특징)를 추출할 수 있는 해리스 연산자(Harris operator)가 예시임.
특징 엔지니어링(feature engineering)이라고 알고 있는 정보 특징 생성 프로세스(process of inventing informative features)는 고급 주제로 다뤄짐.
특징을 먼저 만들어줘야 좋은 특징을 선택&사용 할 수 있음.
알고리즘을 선택하기 전에 먼저 특징을 만들어 놓는 것이 알고리즘 사용에 있어 더 중요함.
4장에서 특징 엔지니어링을 자세히 다룰 것임.
마지막으로, 지도학습에서 사용하는 모든 데이터는 레이블이 있어야함.
특정 종류의 사물(ex. 개 or 고양이), 특정 가격(ex. 주택 가격)과 같은 레이블이 있어야 데이터를 식별 할 수 있음.
결국, 지도 머신러닝 시스템의 목표는 테스트 세트의 모든 데이터 포인트의 레이블을 예측하는 것임.
- 훈련 데이터의 규칙성을 학습하고
- 함께 제공된 레이블을 사용하여
- 테스트 세트에서 성능을 테스트 하는 것임.
따라서, 제대로 머신러닝 시스템을 구축 하려면,
먼저, 데이터를 적재, 저장, 조작 방법을 다뤄야한다.
아래부터 OpenCV에서 파이썬으로 이러한 작업들을 배울 것이다.
OpenCV와 파이썬을 사용한 데이터 취급
다양한 종류의 데이터 유형이 있음.
그래서 특정 값에 사용할 데이터 유형을 구별하는 것이 어렵기도 함.
여기서는 표준 데이터 유형을 유지할 스칼라 값을 제외한 모든 것을 배열로 처리해 단순성을 유지할 것임.
이미지는 폭과 높이가 있기 때문에 2D 배열이 됨.
1D 배열의 예시로는 시간이 지남에 따라 강도가 변화하는 사운드 클립을 예로 들 수 있음.
OpenCV의 C++ API를 계속 사용하고 앞으로도 그렇게 할 계획이라면,,
C++에서 데이터를 처리하는 것이 다소 어려울 수 있음.
C++ 언어의 문법적 오버헤드를 처리해야 할 뿐만 아니라 다양한 데이터 유형과 플랫폼 간의 호환성 문제와 씨름 해야한다.
하지만, OpenCV 파이썬 API를 사용하면 SciPy(Scientific Python) 커뮤니티에서 제공하는 다수의 오픈소스 패키지에 자동으로 액세스 할 수 있기 때문에 프로세스가 대폭 간소화 됨.
많은 과학 연산 도구를 제공하는 NumPy(Numerical Python) 패키지가 그 중 하나임.
파이썬 NumPy 패키지를 사용한 데이터 취급
아나콘다를 설치했다면 이미 NumPy도 설치 되어있음.
NumPy에 익숙해지면 파이썬 세계에서 가장 과학적인 컴퓨팅 도구를 주변에 구축한 것임.
여기에는 OpenCV가 포함돼 있으므로, NumPy 학습에 소요되는 시간에서 결국 이득..
NumPy를 시작하는 방법을 간략히 설명할 건데,
고급 수준의 파이썬 사용자라면 이 절을 건너뛰어도 무방..!
NumPy 가져오기
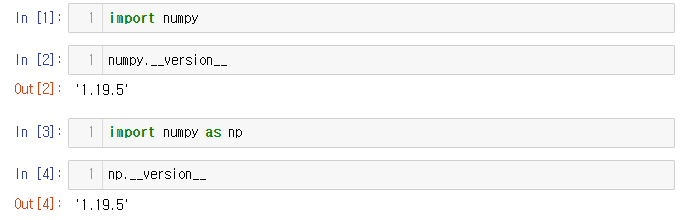
일반적으로 과학적인 용도로 파이썬을 사용할 때, np를 별칭으로 NumPy를 가져온다.
NumPy 배열의 이해

파이썬은 type에 유연한 언어임.
즉, 새 변수를 만들 때마다 데이터 유형을 지정할 필요가 없음.
착하게 정수라고 자동 지정되네
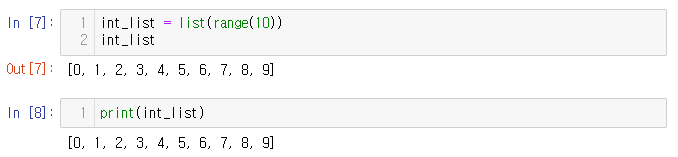
파이썬에서 표준 다중 요소 컨테이너인 list() 명령을 사용해 정수 리스트를 만들 수 있는데,
range(x) 함수는 0부터 x-1까지의 모든 정수를 나타내며, 생성함.
변수를 출력하려면 print 함수를 사용하거나 변수 이름을 입력하고 Enter를 누른다.
파이썬에서 정수 리스트 int_list의 모든 요소를 반복하고
각 요소에 str() 함수(숫자를 문자열로 변환하는 함수)를 적용해 문자열 리스트를 만들 수 있다.

리스트는 수학에서 사용하기에 적합하지 않을 수 도있음.
예를 들어 int_list의 모든 요소에 2를 곱하고 싶을 때
그냥 int_list * 2를 하게되면 아래와 같이 모든 요소를 두 번 반복하는 꼴이 된다.

이제 NumPy를 사용하면 파이썬에서 배열 산술 연산을 쉽게 수행할 수 있다.
정수 목록을 NumPy 배열로 신속하게 변환할 수 있음.

그리고 곱셈을 수행하면 아래와 같이 우리가 원하는 곱셈을 수행.

더하기, 빼기, 나누기, 기타 여러 기능을 이와 동일하게 사용할 수 있음.
또한 모든 NumPy 배열에는 아래와 같은 속성이 있음.
ndim: 차원 수
shape: 각 차원의 크기
size: 배열의 총 요소 수
dtype: 배열의 데이터 유형 (예, int, float, string 등)
정수 배열에서 앞의 속성들을 확인 해보즈아..!

해석 :
10개의 요소를 포함하는 1차원이 존재하고, 모든 요소는 32비트 정수임.
(내가 32비트 시스템이라서 int32인거임)
인덱싱을 통해 단일 배열 요소에 액세스
파이썬의 표준 리스트 인덱스(indexing)사용에 익숙하다면 NumPy의 인덱스 생성도 익숙할 것임.
1D 배열에서 i번째 값(0부터 시작)은 파이썬 목록에서와 같이 대괄호로 원하는 인덱스를 지정해 액세스 할 수 있다.
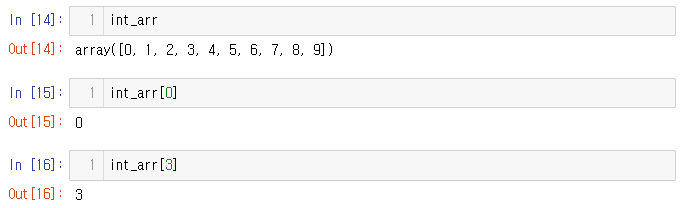
배열 끝의 인덱스를 사용하려면 음수 인덱스..!
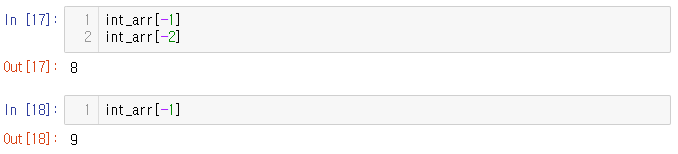
In [17]처럼 Line 1은 실행되지만, Line 2는 마지막으로 실행되므로 Line 1은 나타나지 않는다.
배열 분할하는 법..!

x[start : stop : step]을 사용한다. 이들 중 하나가 지정되지 않은 경우, default 값은 start = 0, stop = size of dimension, step = 1
다차원 배열 만들기
배열은 리스트에만 국한되지 않고 배열은 임의의 차원을 가질 수 있쥬.
머신러닝에서
열 인덱스는 특정 특징 값을 나타내고
행은 실제 특징 값을 포함하는 2D 배열을 처리한다.
NumPy를 사용하면 다차원 배열을 처음부터 손쉽게 만들 수 있다.
모든 원소를 0으로 초기화한 3행 5열의 배열을 만들고 싶다고 가정하쟈.
데이터 유형을 지정하지 않으면 NumPy는 기본적으로 float를 사용한다.

OpenCV에서 알 수 있듯이, 이 배열의 모든 픽셀은 0(검은색)으로 설정한 3X5 크기의 그레이스케일 이미지다. 예를 들어 세 개의 컬러 채널(R, G, B)을 갖는 작은 2X4 픽셀 이미지를 만들고, 모든 픽셀을 흰색으로 설정하려면 NumPy를 사용해 3X2X4크기의 3D 배열을 만든다.
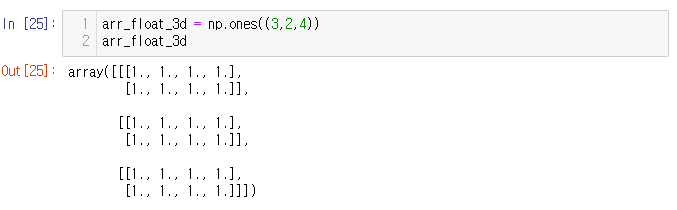
여기서 첫 번째 차원은 색상 채널을 정의한다.
따라서 이것이 실제 이미지 데이터라면 배열을 잘라 첫 번째 채널의 색상 정보를 쉽게 얻을 수 있음.

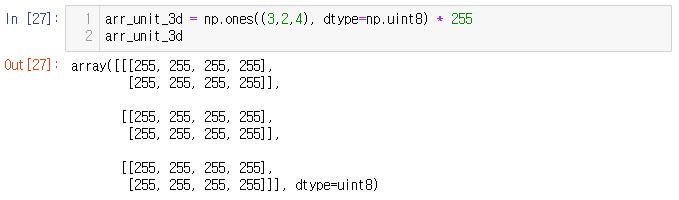
OpenCV에서 이미지는
- 0과 1사이의 값을 갖는 32비트 부동소수점 배열로 제공되거나
- 0과 255 사이의 값을 갖는 8비트 정수 배열로 제공된다.
따라서, NumPy 배열의 dtype 특성을 지정하고 배열의 모든 요소에 255를 곱해 8비트 정수를 사용하는 2X4 픽셀의 완전 흰색 RGB 이미지를 만들 수 있다..!!!
이후 좀 더 발전된 배열의 사용 방법은 3장에서 살펴보즈아 !
파이썬에서 외부 데이터 세트 불러오기
SciPy 커뮤니티로 인해 사용하고자 하는 데이터에 대한 많은 리소스를 얻을 수 있다.
특히 유용한 리소스는 scikit-learn의 sklearn.datasets 패키지 형태로 제공된다.
이 패키지에는 외부 웹 사이트에서 파일을 다운로드할 필요가 없는 작은 데이터세트가 사전에 설치돼 있음.
이러한 데이터 세트에는 아래의 항목들을 가진다.
load_boston:- 보스턴의 다른 교외 지역에 대한 주택가격, 도시별 일인당 범죄율, 주거용 토지비율, 비소매업의 수 등의 특징을 포함한 데이터 세트.
load_iris:- iris는 불꽃이라는 뜻으로, 세 가지 다른 꽃잎(setosa, versicolor, virginica), 꽃받침과 꽃잎의 너비와 길이를 설명하는 네 가지 특징 포함한 데이터 세트.
load_diabetes:- 당뇨병여부, 연령, 성별, 체질량 지수, 여섯개의 평균 혈압과 혈청 측정 결과 등의 특징을 포함한 데이터 세트.
load_digits:- 0~9 숫자의 8x8 픽셀 이미지를 포함한 숫자 데이터 세트.
load_linnerud:- 피트니스 클럽에서 20명의 중년 남성에게서 측정한 3개의 생리학상 변수와 3개의 운동 관련 변수를 포함한 데이터 세트.
또한 scikit-learn을 사용하면, 다음처럼 외부 저장소에서 직접 데이터 세트를 다운로드할 수 있음.
fetch_olivetti_faces:- 40개의 서로 다른 주제를 가진 다른 이미지 10개가 포함된 올리베타(Olivetaa) 얼굴 데이터 세트
fetch_20newsgroups:- 20개의 주제에 대한 18,000개의 뉴스 그룹 게시물을 포함하는 뉴스 그룹 데이터 세트.
게다가 http://openml.org 의 머신러닝 데이터베이스에서 직접 데이터 세트를 다운로드 가능.
예를 들어, 다음처럼 아이리스 데이터 세트를 다운로드 할 수 있음.

iris 꽃 데이터베이스에는 꽃받침 길이, 꽃받침 폭, 꽃잎 길이, 꽃잎 폭 등 4가지 특징을 가진 총 1500개의 샘플이 포함돼 있음.
데이터는 3 가지 등급으로 나뉜다.
- 아이리스 세토사
- 아이리스 베르시콜루어
- 아이리스 버지니카
데이터와 레이블은 두 개의 별도 컨테이너로 전달되고, 다음처럼 확인할 수 있다.

여기서 iris_data에는 각각 4개의 특징을 가진 150개의 표본이 포함되어 있다.
레이블은 iris_target에 저장되며, 레이블은 샘플당 하나만 있다.
모든 목푯값을 자세히 확인할 수는 있지만 모든 것을 출력하지 않는다.
대신 NumPy를 사용해 쉽게 수행할 수 있는 모든 목푯값을 확인하고자 한다.

Matplotlib을 사용한 데이터 시각화
Matplotlib은 NumPy 배열을 기반으로하는 다중 플랫폼 데이터 시각화 라이브러리.
2002년 존 헌터(John Hunter)에 의해 만들어 졌음.
원래 IPython에 대한 패치로 설계됐고,
커맨드라인에서 대화형 MATLAB 스타일 플로팅이 가능하게 됐음.
최근 몇 년 동안 Matplotlib(R 언어의 ggplot과 ggvis 등)을 대체하고자 더 새롭고 유용한 도구가 등장했지만 Matplotlib은 잘 테스트 된 크로스 플랫폼 그래픽 엔진으로 필수적이다.
파이썬 아나콘다 스택을 설치 했다면 이미 Matplotlib이 설치돼있고 사용할 수 있다.

인터페이스 plt는 이 책 전반에 걸쳐 자주 사용함.
첫 번째, 플롯(plot)을 만들어보자.
플롯(plot)이란 ?
그래프 그리기의 의미로 해석될 수 있으며, 일반적으로 "플롯을 만든다."라고 사용됨.
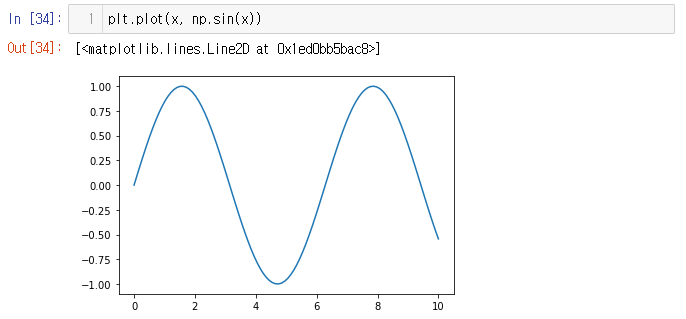
사인 함수 sin(x)를 만들고 싶다고 가정해보자.
함수는 x축의 모든 포인트에서 대응돼야 한다.
여기서는 0 ≤ x ≤ 10의 범위를 가진다.
NumPy의 linspace 함수를 사용해 x축 0에서 10까지의 선형 간격을 만들고
총 100개의 샘플링 포인트를 만든다.

NumPy의 sin함수를 사용해 모든 포인트 x에서 sin 함수를 계산하고, plt의 plot함수를 호출해 결과를 시각화 할 수 있다.
주피터 노트북에서 ploting :
%matplotlib notebook: 이 노트북과 관련된 대화형 플롯으로 연결됨.
%matplotlib inline: 노트북에 연결된 플롯의 정지 이미지를 볼 수 있음.
이 책에서는 일반적으로 인라인(inline)옵션을 사용한다.
%matplotlib notebook실행 예시
%matplotlib inline실행 예시
그림 저장하고 싶을때는 ?

ipynb파일이 있는 위치에 저장된다.
Matplotlib을 가져온 후 plt.style.use(style_name)을 실행한다. 사용 가능한 모든 스타일은 plt.style.available에서 볼 수 있다. 예를 들면 아래와 같이 사용하면 된다. plt.style.use('fivethirtyeight')
plt.style.use('ggplot')
plt.style.use('seaborn-dark')
게다가 plt.xkcd()를 사용해 다른 형태를 나타낼 수 있다.
외부 데이터 세트의 데이터 시각화
scikit-learn의 digits 데이터 세트와 같은 외부 데이터 세트의 일부를 시각화 해보자.
시각화 하려면 아래와 같은 세 가지 도구가 필요하다.
- 실제 데이터에 대한 scikit-learn
- 데이터 처리용 NumPy
- Matplotlib
먼저 라이브러리를 가져오고

첫 단계에서는 실제 데이터를 가져온다.

기억하는가? digits는 실제 이미지 데이터를 포함하는 data필드와 이미지 레이블을 포함하는 target필드 라는 두 가지 필드로 구성된다.

이때, 첫 번째 차원은 데이터 세트의 이미지 수에 해당함.
data는 모든 픽셀을 하나의 큰 벡터에 정렬하는 반면,
images는 각 이미지의 8x8 공간 배열을 유지함.
따라서, 단일 이미지를 플롯하길 원한다면
images필드가 더 적절할 것이다.
먼저 NumPy의 배열 슬라이싱(array slicing)을 사용해 데이터 세트에서 하나의 이미지를 가져오쟈.

이렇게 1797개의 아이템을 갖는 큰 배열에서 8x8=64픽셀의 첫 번째 행을 가져옴.
그리고 plt의 imshow함수를 사용해 이미지를 나타내고 저장한다.
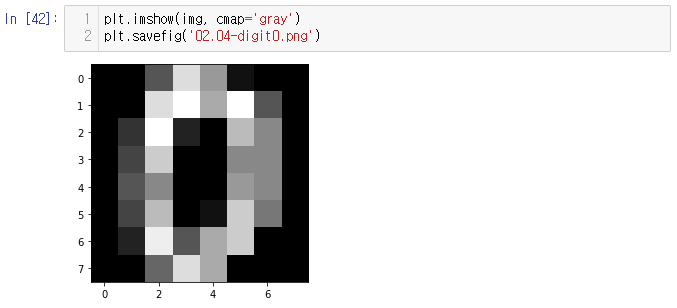
또한, cmap 인수를 사용해서 색상 맵을 지정할 수 있음.
기본적으로 Matplotlib은 MATLAB의 기본 색상 맵 jet을 사용함.
그러나, 그레이스케일 이미지의 경우 그레이(회색) 색상 맵이 더 알맞음.
마지막으로 plt의 subplot함수를 사용해 전체 숫자 샘플을 나타낼 수 있음.
subplot함수는 행 수, 열 수, 현재 subplot 인덱스(1에서 시작)를 지정할 수 있으며, MATLAB과 동일.
for 루프를 사용해 데이터 세트의 처음 10개 이미지를 반복하고, 모든 이미지에 자체 subplot을 할당한다.

C++에서 OpenCV의 TrainData 컨테이너를 사용해 데이터 다루기
생략
요약
2장에서는 원시 데이터에서 유용한 특징을 추출하는 방법,
데이터와 레이블을 사용해 머신러닝 모델을 학습하는 방법,
최종 모델을 사용해 새로운 데이터 레이블을 예측하는 방법을 다뤘다.
이를 통해 머신러닝 문제를 다루는 전형적인 워크플로를 살펴봤다.
모델이 새로운 데이터 포인트로 얼마나 잘 일반화 되는지 알 수 있는 유일한 방법이므로,
데이터를 훈련 세트와 테스트 세트로 분리하는 것이 필수적임을 알게됬음.
소프트웨어 측면에서 파이썬 기술 활용 방법을 많이 살펴봄.
NumPy배열을 사용해 데이터를 저장하고 조작하는 방법
데이터 시각화를 위해 Matplotlib을 사용하는 방법을 배웠음.
그리고 scikit-learn과 많은 유용한 데이터 자원도 이야기 함.
이 도구들을 사용해 이제 실제 머신러닝 모델을 구현할 준비가 됐음.
3장에서는 지도학습(supervised learning)과 두 가지 주요 문제 범주인 분류/회귀에 초첨을 맞춘다.