![[PyTorch & Numpy] 기본 텐서 다루는법의 차이점](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FbmIFPo%2FbtrMdGoDLx6%2FYW1OaihPkKH2eMmNkCs6c1%2Fimg.png)
PyTorch 공부하다가 궁금해진 tensor들 공부하다가 계속 파고드는중에 찾은 나의 개념 오류를 정리하고자한다.
1. PyTorch Tensor Shape Convection
1.1 2D Tensor

1.2 3D Tensor
1.2.1 for Computer Vision

(batch size, width, height)
(배치사이즈, 너비, 높이)
1.2.2 for NLP
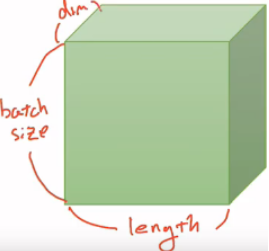
(batch size, length, dim)
(배치 사이즈, 문장 길이, 단어 벡터의 차원)
2. Numpy로 Tensor 만들기(벡터와 행렬 만들기)
2.1 1D with Numpy
ndim : 몇 차원인지
shape : 크기 출력
import numpy as np
t = np.array([0., 1., 2., 3., 4., 5., 6.]) # List 생성해서 1차원 array로 변환.
print(t)
print('Rank of t:', t.ndim) # t의 차원
print('Shape of t:', t.shape) # t의 크기Rank of t: 1
Shape of t: (7,)t는 1차원의 벡터이다.
t는 1x7의 크기를 가지는 벡터이다.
(7,) = (1, 7) = (1x7) = 1행 7열
*참고* 1차원 = 벡터 = 1차원 텐서 / 2차원 = 행렬 = 2차원 텐서 / 3차원 이상 = 텐서
2.2 2D with Numpy
t = np.array([[1,2,3], [4,5,6], [7,8,9], [10,11,12]])
print(t)
print("\n Rank of t:", t.ndim) # t의 차원은 2차원.
print("\n Shape of t:", t.shape) # t의 크기는 (4,3)=4x3=4행 3열[[ 1 2 3]
[ 4 5 6]
[ 7 8 9]
[10 11 12]]
Rank of t: 2
Shape of t: (4, 3)
이제 넘파이로는 그만 만들고 3차원 텐서 부터는 PyTorch로 만들어서 Numpy와 PyTorch를 비교해보자.
3. 파이토치로 텐서 선언하기(PyTorch Tensor Allocation)
3.1 1D with Pytorch
import torch
t = torch.FloatTensor([0., 1., 2., 3., 4., 5., 6.]) #위 numpy예제처럼 똑같이 PyTorch로 tensor선언
print(t)
print(t.dim())
print(t.ndim)
print(t.shape)
print(t.size())tensor([0., 1., 2., 3., 4., 5., 6.])
1
1
torch.Size([7])
torch.Size([7])여기서 재밌는게
print(t)
print(t.dim())
print(t.ndim)
print(t.shape)
print(t.size())여기서 dim과 size에 괄호가 추가됬잖아? 괄호 안하고 run하면
tensor([0., 1., 2., 3., 4., 5., 6.])
<built-in method dim of Tensor object at 0x7fce6fff2470>
1
torch.Size([7])
<built-in method size of Tensor object at 0x7fce6fff2470>이런식의 output이 나오는데
그래서 괄호를 치는 이유가 정확히 뭔지는 모르겠지만 느낌상으로는, 단순히 array가 아니라 객체로써 tensor를 인식하기때문에 괄호가 있어야 하는 느낌인데.
정확히 아시는분 댓글 남겨주시면 감사하겠습니다..!
3.2 2D with PyTorch
t = torch.FloatTensor([[1., 2., 3.],
[4., 5., 6.],
[7., 8., 9.],
[10., 11., 12.]
])
print(t)
print(t.dim()) # rank. 즉, 차원
print(t.size()) # shapetensor([[ 1., 2., 3.],
[ 4., 5., 6.],
[ 7., 8., 9.],
[10., 11., 12.]])
2
torch.Size([4, 3])
3.3 브로드캐스팅(Broadcasting)
브로드캐스팅이란? :
파이토치에서 제공하는 기능의 한 종류
크기가 다른 행렬 또는 텐서에 대해서
사칙연산을 수행할 때
자동으로 크기를 맞춰서 연산을 수행하게 만드는 기능.
정확하게는 numpy에도 있다.
아마 numpy에서는 배열에 대한 브로드캐스팅이고,
pytorch에서는 '텐서'에 대한 브로드캐스팅이라서
이렇게 구분해서 쓴 것 같다.
# Vector + scalar
m1 = torch.FloatTensor([[1, 2]])
m2 = torch.FloatTensor([3]) # [3] -> [3, 3]
print(m1 + m2)tensor([[4., 5.]])m1은 1x2 텐서
m2는 1x1 텐서
여기서 m1 + m2는 원래 진행 할 수 없지만, pytorch가 m2를 1x2 텐서로 변경하여 연산 수행한다.
다른 예시 들어보면
# 1x3 Vector + 3x1 Vector
m1 = torch.FloatTensor([[1,2,3]])
m2 = torch.FloatTensor([[3],
[4],
[5]])
print(m1 + m2)tensor([[4., 5., 6.],
[5., 6., 7.],
[6., 7., 8.]])# 브로드캐스팅 과정에서 실제로 두 텐서가 어떻게 변경되는지 보겠습니다.
[1, 2, 3]
==> [[1, 2, 3],
[1, 2, 3]
[1, 2, 3]
[3]
[4]
[5]
==> [[3, 3, 3],
[4, 4, 4],
[5, 5, 5]]이렇게 브로드캐스팅은 편리하지만, 데이터를 다루는 사람이라면 항상 조심해야한다.
두 텐서의 크기가 같다고 착각해서 덧셈하는 순간 데이터는 쓰레기가 되는거고 문제 발생시 원인으로 찾기도 어려울 것이다.